To celebrate the 20th anniversary of Harry Potter, we like to highlight a Text-Mining project that was recently implemented by Markus Dienstknecht and Moritz Haine from the Department of Data Science and Knowledge Engineering of the Maastricht University: spell extraction from the iconic seven Harry Potter books.

Objective of the project was to extract all spells that were used in the Harry Potter books and assign them to the characters who used them. By using text-mining techniques to answer the W-questions (Who cast a spell? What did a character cast? Why did the character cast that spell? What goal did he try to achieve? Whom did he use that spell against? Where did he use that spell?) the team aimed for a complete spell – character mapping with additional information.
253 DIFFERENT SPELLS FROM 7 BOOKS FOUND IN 25 MINUTES
In 25 minutes, using a Core i7 machine and 16GB RAM, the computer extracted 41 different wizards, 64 different spells and 253 spells in total. The results are visualized with Gephi.
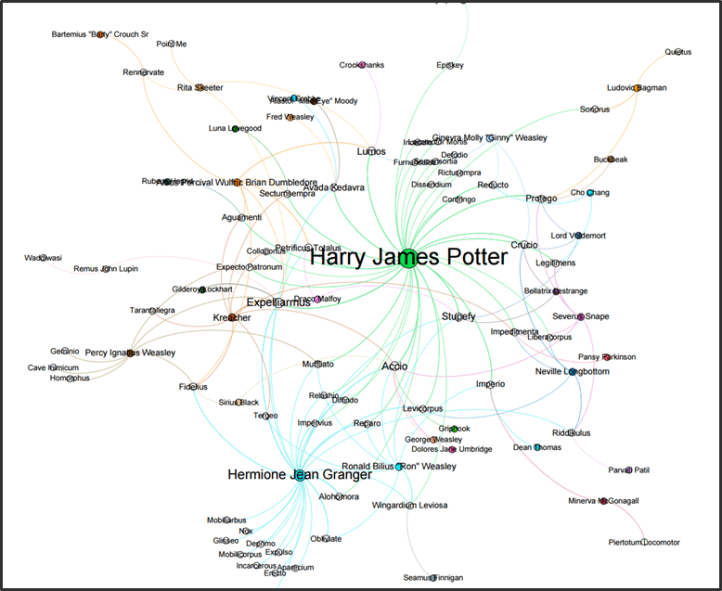
THE HUNT FOR THE SPELL
The first thing that had to be done in order to relate spells to individuals, was to extract every spell that was used. For that goal, several integrated text mining approaches were used. Preprocessing was needed to make sure that non-relevant information was removed (like Page | XX or empty lines). A manual check through all the given sentences was made to make sure all quotation marks were used correctly.
Tagging and Named Entity Recognition (NER) based on gazetteers, part-of-speech (POS) tagging and linguistic statistics were used on the separated sentences to indicate the spells and the individuals..
The final step of reducing all the words to a minimum number of words was to check the endings of all the leftover words. This proved to be effective as almost every spell is of Latin origin and the Latin grammar is straightforward and has very specific suffixes. By using this additional information, the spells could be recognized and assigned to a person and a location.
Thank you Markus Dienstknecht and Moritz Haine for a great project!
See also a larger feature article on this project on the website of the University of Maastricht: Spell Extraction with Text Mining at DKE
